Harnessing your data for human ingenuity
Reliable data. Faster decisions. Better execution.


Challenge. Learn. Transform.
We'll guide you every step of the way

We design resilient data architectures that combine robust foundations with modern BI, Machine Learning, and agentic workflows
eaQbe is a Brussels-based consultancy specialising in artificial intelligence, founded in 2020. We help organisations across Belgium and the EU build reliable data foundations, then turn them into operational systems: BI solutions that guide decisions, machine learning models built for specific tasks, and agentic AI workflows that automate complex operations. Alongside consulting & solutions, eaQbe delivers hands-on, scenario-based training in AI and data. Everything we deliver is built on one principle: operational autonomy.
Our solutions
Three levers to turn data into operational results
Our methodology
A structured consulting approach grounded in CRISP-DM and delivered through Scrum
1. Frame the challenge
We start by structuring the project at business level: stakeholder alignment, governance setup, and qualitative interviews across departments. Through steering committees and structured discussions, we clarify objectives, success criteria, constraints, and interdependencies. In parallel, we assess available data sources to ground decisions in operational reality.

2. Build and iterate
We translate business objectives into data pipelines and models. This phase covers features engineering, and iterative modeling, with frequent validation points. Working in short cycles, we test assumptions, refine configurations, and ensure models remain explainable, robust, and aligned with business intent.

3. Validate and operationalize
We evaluate results against the initial business objectives. Once validated, we deploy solutions into existing systems, support user adoption, and document outcomes. This phase closes the loop with stakeholders and sets the foundation for continuous improvement.

From passion to impact eaQbe
Built on a deep commitment to data science and technology, we are driven by a bold vision: making data science accessible, actionable, and transformative for businesses of all sizes.
Expertise
We bring engineering-level rigor to business constraints, turning complex data into reliable systems.
Innovation
We continuously explore new methods, architectures, and workflows to better align technology with business realities.
Learning
We design our work to build autonomy, by breaking complexity down, transferring knowledge, and enabling teams to operate, adapt, and improve over time.
Trusted by







Our Achievements
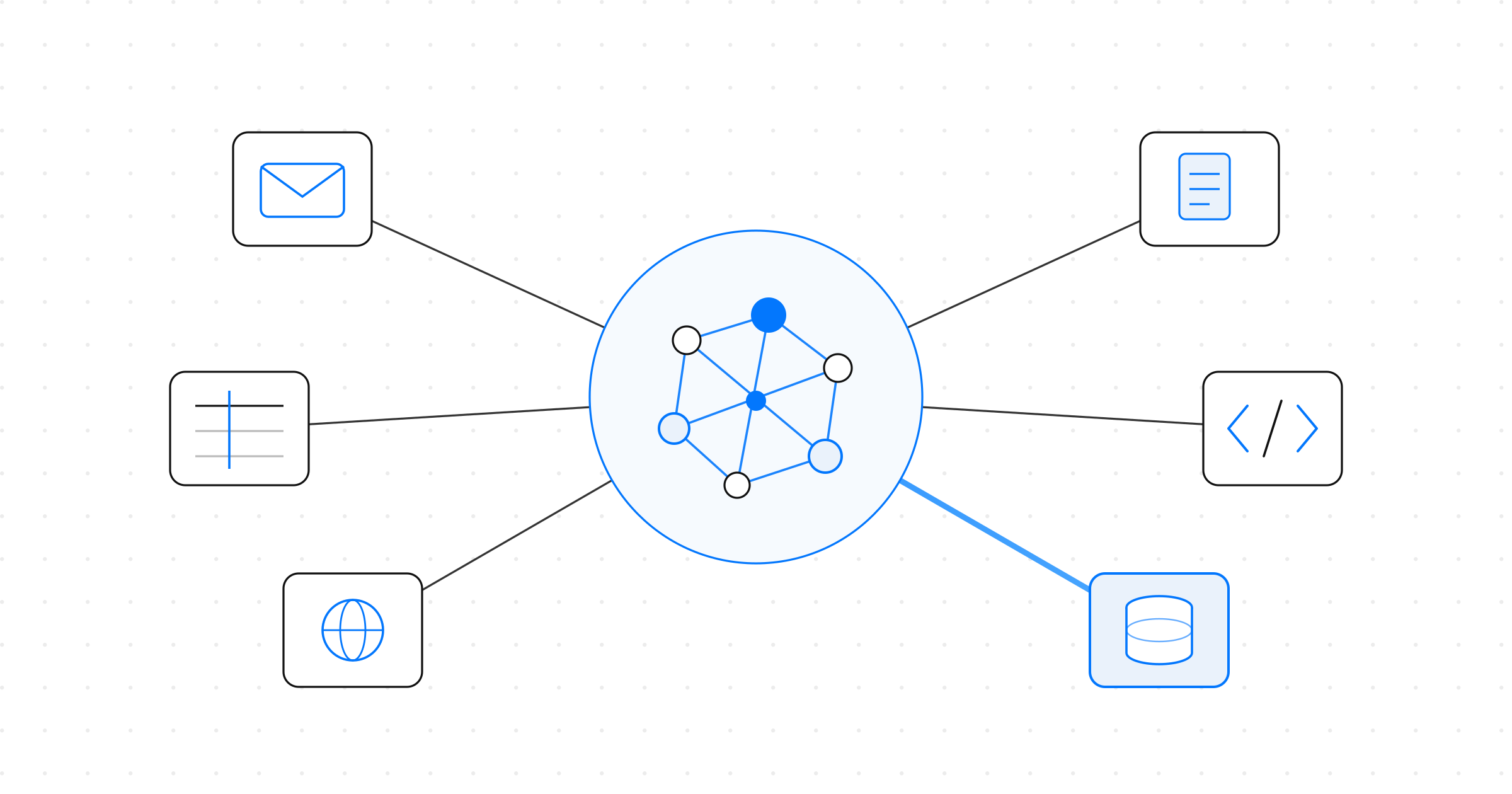
Data Systems Building Blocks
We design and integrate the right components to build reliable, maintainable data systems within your existing environment.
✦ Contact us















Read our latest resources on docs.eaQbe.com
Demystifying Neural Networks & Deep Learning
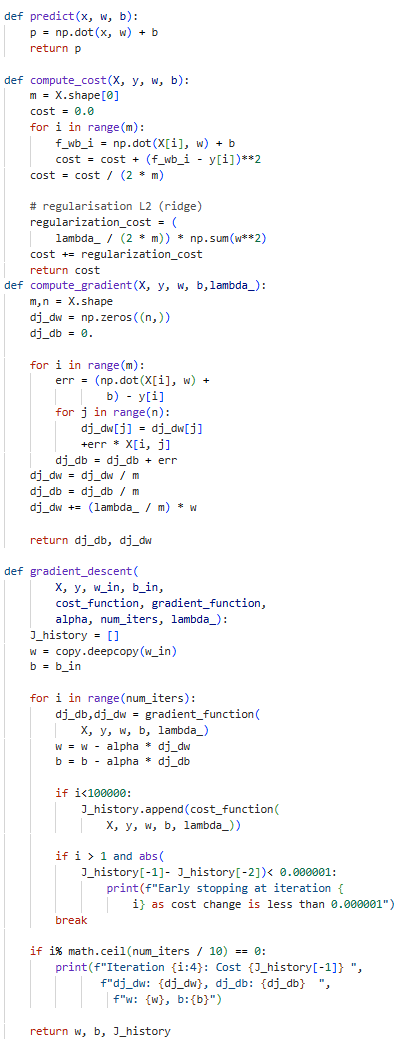
A comprehensive guide to understanding the "Black Box" of hidden layers. Learn how hardware evolution and Big Data revived Neural Networks, and explore the math behind Gradient Descent and Activation Functions.
Decision Trees & Ensemble Methods
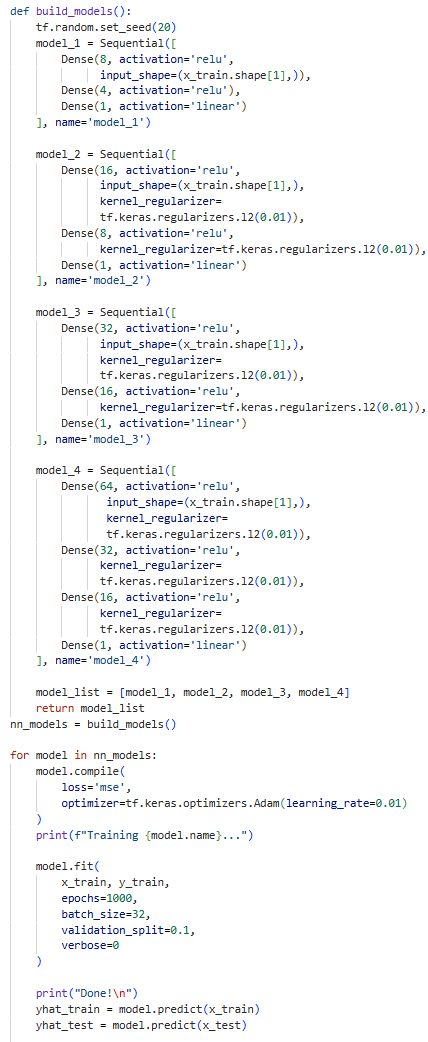
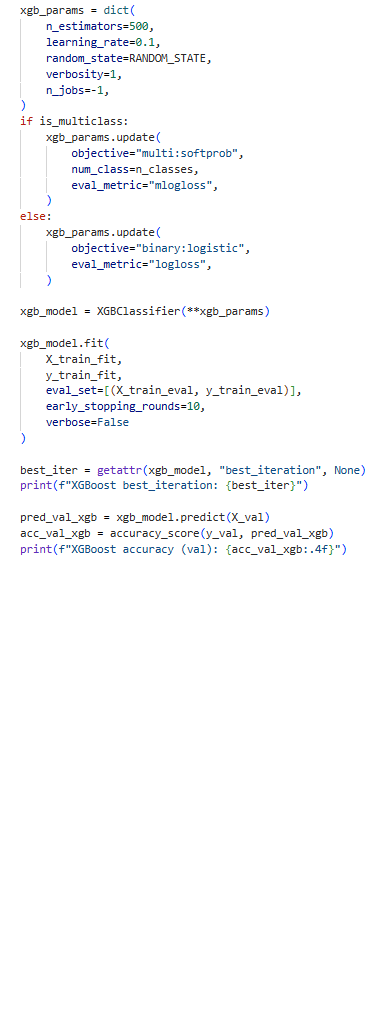
A comprehensive guide to interpretable supervised learning. Understand the mechanics of recursive partitioning and Information Gain, and learn how to evolve simple trees into powerful Random Forest and XGBoost models.
CRISP-DM: The Data Science Lifecycle
The essential framework for managing data science projects. Master the six iterative phases, from Business Understanding to Deployment ; and learn to combine CRISP-DM with SCRUM to transform raw data into actionable value.

Subscribe to our newsletter!
Stay ahead of the curve with our latest insights on AI, data engineering, and digital workflows.